Open search best practices
It’s important to follow aws best practices around shard sizing for OpenSearch or elastic search, these links are helpful:
- https://docs.aws.amazon.com/opensearch-service/latest/developerguide/bp.html
- https://repost.aws/knowledge-center/opensearch-rebalance-uneven-shards
- https://docs.aws.amazon.com/opensearch-service/latest/developerguide/sizing-domains.html#bp-sharding
- https://aws.amazon.com/blogs/opensource/open-distro-elasticsearch-shard-allocation
Some general info about shards
Sharding distributes workload across the cluster nodes. When you push data into the search engine, that data is partitioned into shards and split into primary and replica shards. By default, OpenSearch has 5 primary (independent partitions of a full dataset) and 1 replica shard (a full set copy of the primaries so takes up the same amount of disk space). Replicas provide redundancy and read capacity, it is recommended you have at least 1. Each shard resides on different nodes.
Optimum shard distribution means shards spread evenly across nodes, if you can achieve this, then resource usage across the nodes will also be equal.
To help achieve this, your total shard count per index should be a multiple of the number of data nodes e.g. if you have 12 shards for an index, then you should have 2, 3, 4, 6, or 12 data nodes. Also note that the total number of shards per node is recommended to be 25 shards per 1 b of JVM heap memory on the node, with a hard limit of 1,000 shards on a node.
Your shards should be sized between 10gb - 30 gb (for search heavy workloads) or 30gb - 50gb (for log write-heavy workloads).
Use the follow command to check shard allocation:
curl https://<search-domain-endpoint>.com/_cat/allocation?v
FreeStorageSpaceTooLow alerts
This alert refers to the ebs volume attached to the hot nodes. An initial response may be to increase the storage size but be careful as this may trigger a blue/ green cluster deploy which can take a long time to fully deploy. If you do opt for this method, be sure to also adjust iops and throughput accordingly to avoid throttling notifications.
More effective methods are:
- Increase the number of data nodes (this will not rebalance the shards, so you will still have a storage issue but is useful if you need a bit of breathing room for incoming data and can be used in combination with other methods)
- Delete old indices (immediately effective but might be hard to know which indices are ok to be deleted)
- Move large indices to warm storage (requires some free space to move the indices)
Connecting to the Elastic search api
In order to run commands against the search tools api, you will need to be in a whitelisted ip block. That includes blocks within the Cloud Platform kubernetes cluster.
run the following to create a shell that you can run commands from:
kubectl run curl-pod -n <your-namespace> --image="alpine/curl" --restart=Never --rm -it -- /bin/sh
Connecting to the OpenSearch api
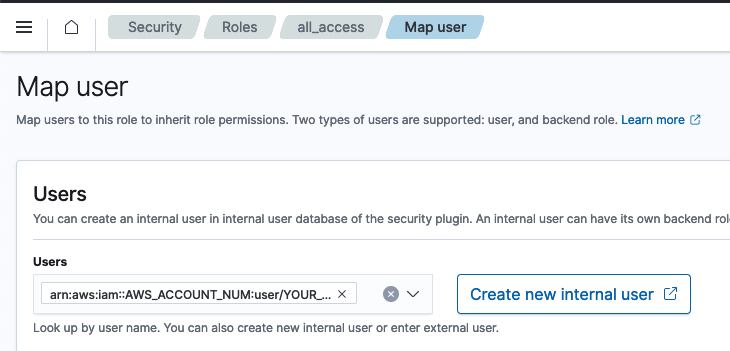
Because we have fine-grained access enabled on OpenSearch, connection isn’t based on ip. It’s based on SAML. To link your cli with OpenSearch, there is a manual step of adding your AWS user arn to the all_access OpenSearch role.
- login to the OpenSearch dashboard using github via SAML
- as a webops team member, you have permissions to edit roles, so head to Security -> Roles ->
all_access(see screenshot below)
Verify you’re connected to the api
list all the indices and their size with the following curl command
curl https://<search-domain-endpoint>.com/_cat/indices
Deleting old indices
Once you’ve identified the index to delete, you can use the following command:
curl -X DELETE "https://<search-domain-endpoint>/<index-name-to-delete>?pretty"
Migrating indices from a hot node to a warm node
https://docs.aws.amazon.com/opensearch-service/latest/developerguide/ultrawarm.html#ultrawarm-migrating
curl -X POST https://<search-domain-endpoint>.com/_ultrawarm/migration/<index-name>/_warm
and get the migration status with:
curl https://<search-domain-endpoint>.com/_ultrawarm/migration/_status?v