OpenSearch Log Restore Runbook
This runbook explains how to restore cold indices logs in OpenSearch as part of our Index State Management (ISM) policy.
Log Availability in OpenSearch
Our OpenSearch Index State Management (ISM) policy is configured as follows:
Hot to Warm: after 1 day
Warm to Cold: after 30 days
Cold to Delete: after 366 days
What does this mean
Logs stored in hot and warm indices are fully visible in the OpenSearch console. As a result, logs from the past 30 days are available by default.
However, cold indices are not searchable in the console - this is expected behavior. Logs are stored in cold storage for long-term retention and cost efficiency.
To access logs older than 30 days, we need to manually migrate the relevant cold indices back to the warm tier, which makes them searchable again.
There are two ways to restore logs from cold storage, depending on the volume of log required.
Option 1: Restoring Cold Indices to Warm via Console
If only a few days of logs are needed, you can restore them manually using the OpenSearch UI:
- Navigate to:
Index Management→Cold Indexestab. Find the required index, and click
Move to warm.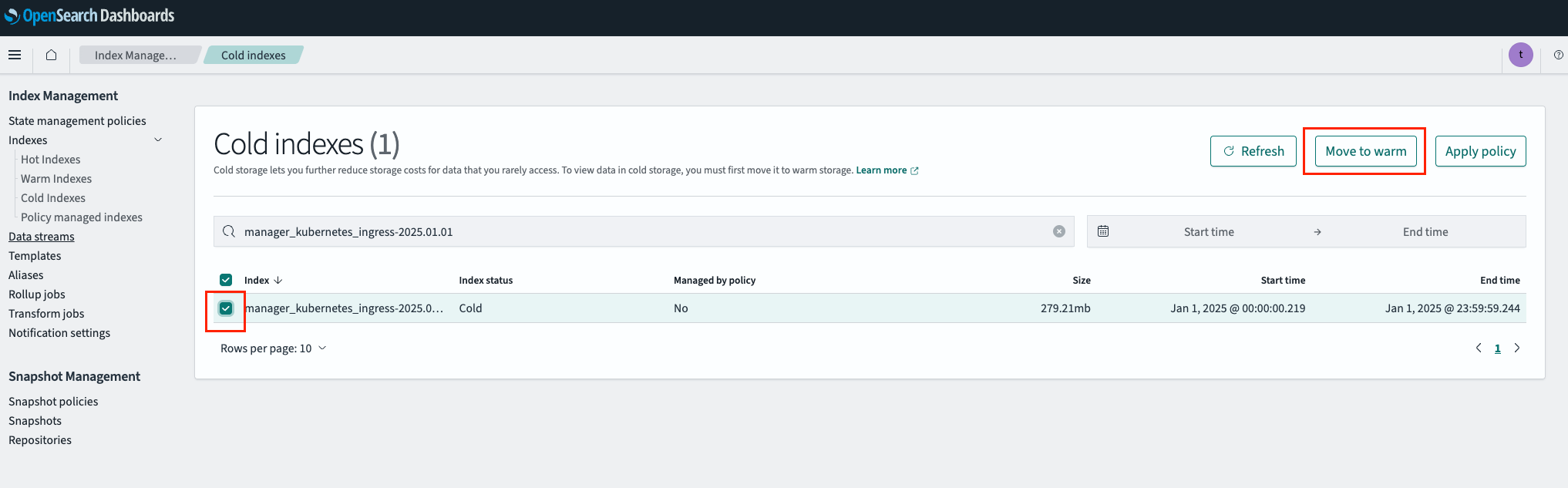
Click
Move index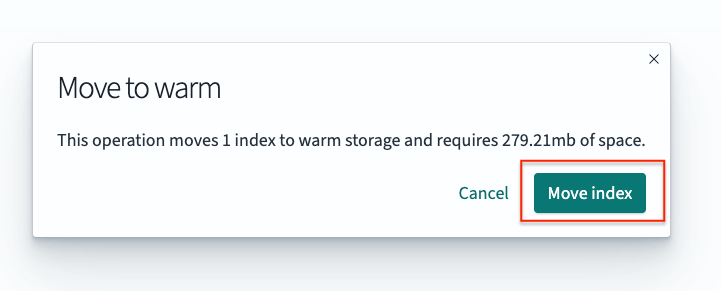
After log investigation is complete and the logs are no longer needed, move the warm index back to cold from the
Warm Indexestab.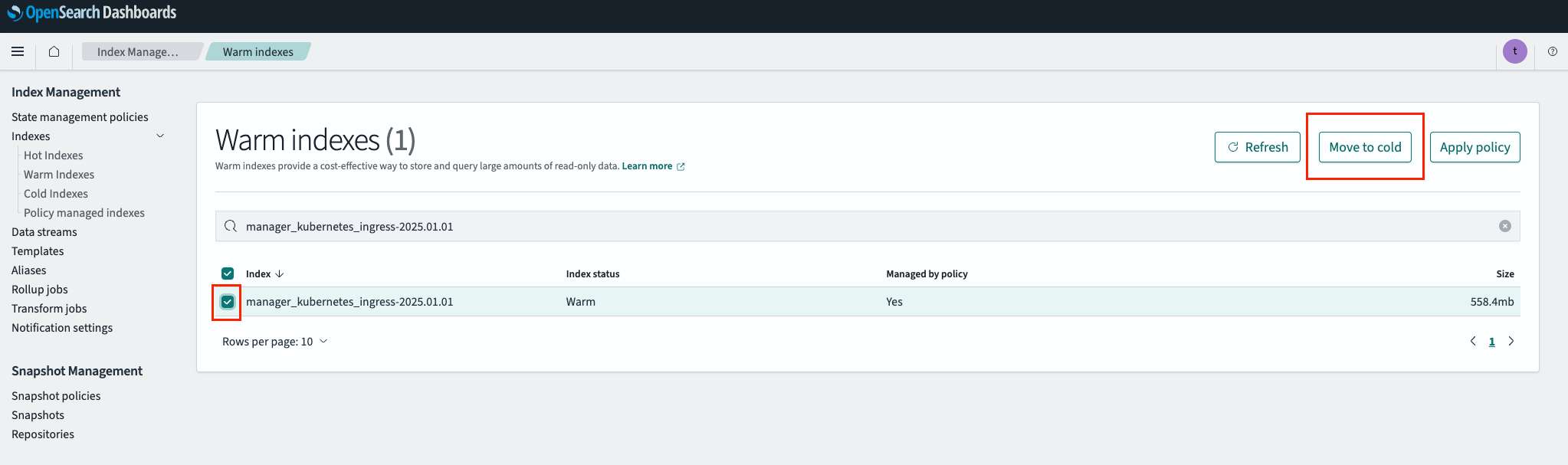
Choose
Calculate from timestamp field, select@timestamp, then clickMove index.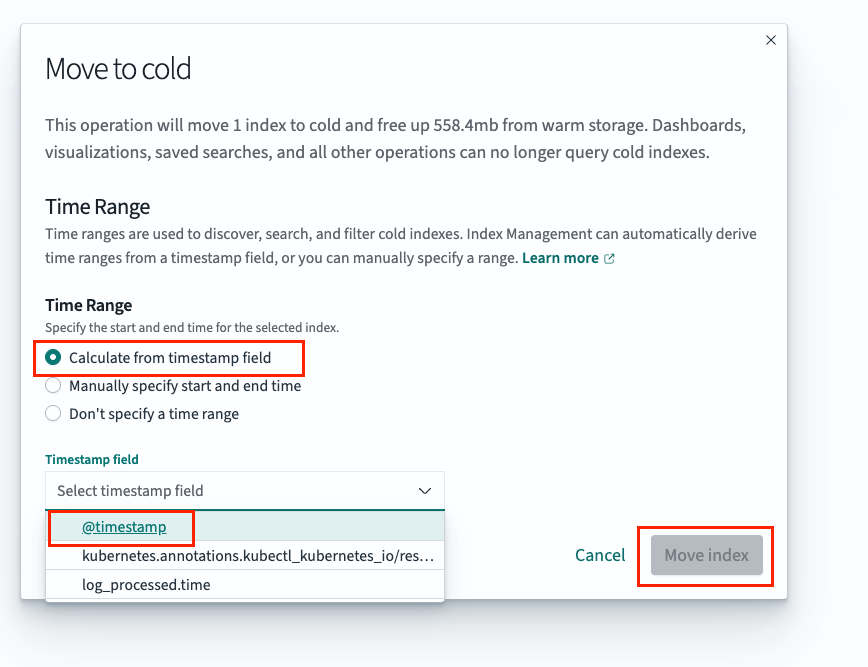




This method is suitable for restoring small batches of logs or ad-hoc investigations.
Caution with Large Restore
Restoring large numbers of cold indices:
- Adds load to the OpenSearch cluster
- Increases hot instance resource usage
- May impact live OpenSearch cluster performance for other users
For large restore operations, use the automation method below.
Option 2: Restoring Large Volumes of Logs via Concourse Pipeline Automation
For large-scale log restores, we use Concourse pipeline automation to restore logs into a separate, non-production OpenSearch cluster to avoid load on the live environment.
Overview
We maintain two pipelines:
Snapshot Creation on the Live OpenSearch pipeline
- Reads from a maintained source index file in S3
- Migrates cold indices to warm.
- Takes snapshots to an S3 snapshot repository.
- Tags completed snapshots with a
snapshot-taken-prefix. - Moves indices back to cold.
Snapshot Restore on a Separate OpenSearch pipeline
- Restores the snapshots using the same source list.
- Skips indices already marked as restored.
- Sets replicas to
0for speed and cost-efficiency. - Waits for shard recovery and green index health.
- Moves the index to the warm tier.
Usage Guide
Taking OpenSearch snapshots can take 30+ minutes per index depending on shard size and data volume. Follow this process:
- Prepare the restore OpenSearch if needed
On the restore OpenSearch, perform the following setup (if not already done):
- Update the cluster name (but not domain ARN) here
In Security roles, add the following IAM user to the
all_accessrole:arn:aws:iam::754256621582:user/cloud-platform/manager-concourseRegister the S3 snapshot repository:
curl -XPUT -L \ --user "$AWS_ACCESS_KEY_ID:$AWS_SECRET_ACCESS_KEY" \ -H "x-amz-security-token: $AWS_SESSION_TOKEN" \ -H "Content-Type: application/json" \ --aws-sigv4 "aws:amz:eu-west-2:es" \ <new-restore-opensearch-endpoint>/_snapshot/cp-live-app-logs-snapshot-s3-repository \ -d '{ "type": "s3", "settings": { "bucket": "cp-live-app-logs-snapshot-s3-repository", "region": "eu-west-2", "role_arn": "arn:aws:iam::754256621582:role/cp-live-app-logs-snapshot-s3-role" } }'
Update the S3 source index list and cleanup the restored tracking file before running the snapshot pipeline.
s3://cloud-platform-concourse-environments-live-reports/opensearch-snapshots/source-index-list.txt s3://cloud-platform-concourse-environments-live-reports/opensearch-snapshots/snapshot-restored.txtUpdate the restore OpenSearch endpoint here if needed
Unpause the
live-opensearch-takes-snapshotandseparate-opensearch-restores-snapshotpipelinefly -t manager unpause-job -j opensearch/live-opensearch-takes-snapshot fly -t manager unpause-job -j opensearch/separate-opensearch-restores-snapshotTrigger
live-opensearch-takes-snapshoton Concourse.Wait for some batch of snapshots to complete.
Trigger
separate-opensearch-restores-snapshoton Concourse.Pause the pipelines once the restore is complete:
fly -t manager pause-job -j opensearch/live-opensearch-takes-snapshot fly -t manager pause-job -j opensearch/separate-opensearch-restores-snapshotAfter log investigation is complete and the logs are no longer needed, clean up any temporary resources (e.g., snapshots, restored indices in the restore cluster, and snapshot tracking files on S3).